|
Computational photography
|
(papers on light fields are farther down on this page)
|
|

|
Removing Reflections from RAW Photos
Eric Kee, Adam Pikielny,
Kevin Blackburn-Matzen,
Marc Levoy,
To appear in
Proc. CVPR 2025.
(preprint available in
arXiv:2404.14414)
This technology was first demoed
at an Adobe MAX
Sneak Peek in October 2023 ("Project SeeThrough").
See also this
Adobe blog.
|
We describe a system to remove real-world reflections from images for consumer
photography. Our system operates on linear (RAW) photos, with the (optional)
addition of a contextual photo looking in the opposite direction, e.g., using the
selfie camera on a mobile device, which helps disambiguate what should be
considered the reflection. The system is trained using synthetic mixtures of
real-world RAW images, which are combined using a reflection simulation that is
photometrically and geometrically accurate. Our system consists of a base model
that accepts the captured photo and optional contextual photo as input, and runs
at 256p, followed by an up-sampling model that transforms output 256p images to
full resolution. The system can produce images for review at 1K in 4.5 to 6.5
seconds on a MacBook or iPhone 14 Pro. We test on RAW photos that were captured
in the field and embody typical consumer photographs.
|
|


|
Handheld Mobile Photography in Very Low Light
Orly Liba, Kiran Murthy, Yun-Ta Tsai, Tim Brooks, Tianfan Xue, Nikhil Karnad,
Qiurui He, Jonathan T. Barron, Dillon Sharlet, Ryan Geiss, Samuel W. Hasinoff,
Yael Pritch,
Marc Levoy,
ACM Transactions on Graphics 38(6)
(Proc. SIGGRAPH Asia 2019)
This paper describes the technology in Night Sight on Google Pixel 3.
Main and supplemental material in a single document here on
Arxiv.
Click here for an
earlier
article
in the Google Research blog.
For Pixel 4 and astrophotography, see this more recent
article.
|
Taking photographs in low light using a mobile phone is challenging and rarely
produces pleasing results. Aside from the physical limits imposed by read noise
and photon shot noise, these cameras are typically handheld, have small
apertures and sensors, use mass-produced analog electronics that cannot easily
be cooled, and are commonly used to photograph subjects that move, like
children and pets. In this paper we describe a system for capturing clean,
sharp, colorful photographs in light as low as 0.3~lux, where human vision
becomes monochromatic and indistinct. To permit handheld photography without
flash illumination, we capture, align, and combine multiple frames. Our system
employs "motion metering", which uses an estimate of motion magnitudes (whether
due to handshake or moving objects) to identify the number of frames and the
per-frame exposure times that together minimize both noise and motion blur in a
captured burst. We combine these frames using robust alignment and merging
techniques that are specialized for high-noise imagery. To ensure accurate
colors in such low light, we employ a learning-based auto white balancing
algorithm. To prevent the photographs from looking like they were shot in
daylight, we use tone mapping techniques inspired by illusionistic painting:
increasing contrast, crushing shadows to black, and surrounding the scene with
darkness. All of these processes are performed using the limited computational
resources of a mobile device. Our system can be used by novice photographers to
produce shareable pictures in a few seconds based on a single shutter press,
even in environments so dim that humans cannot see clearly.
|
|

|
Handheld Multi-Frame Super-Resolution
Bartlomiej Wronski, Ignacio Garcia-Dorado, Manfred Ernst, Damien Kelly,
Michael Krainin, Chia-Kai Liang,
Marc Levoy,
Peyman Milanfar,
ACM Transactions on Graphics,
(Proc. SIGGRAPH 2019)
Click here for an earlier related article in the
Google Research Blog.
See also these interviews by
DP Review (or
video) and
CNET.
|
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits
their spatial resolution; smaller apertures, which limits their light gathering
ability; and smaller pixels, which reduces their signal-to- noise ratio. The
use of color filter arrays (CFAs) requires demosaicing, which further degrades
resolution. In this paper, we supplant the use of traditional demosaicing in
single-frame and burst photography pipelines with a multi- frame
super-resolution algorithm that creates a complete RGB image directly from a
burst of CFA raw images. We harness natural hand tremor, typical in handheld
photography, to acquire a burst of raw frames with small offsets. These frames
are then aligned and merged to form a single image with red, green, and blue
values at every pixel site. This approach, which includes no explicit
demosaicing step, serves to both increase image resolution and boost signal to
noise ratio. Our algorithm is robust to challenging scene conditions: local
motion, occlusion, or scene changes. It runs at 100 milliseconds per
12-megapixel RAW input burst frame on mass-produced mobile
phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature,
as well as the default merge method in Night Sight mode (whether zooming or
not) on Google’s flagship phone.
|
|

|
Synthetic Depth-of-Field with a Single-Camera Mobile Phone
Neal Wadhwa, Rahul Garg, David E. Jacobs, Bryan E. Feldman, Nori Kanazawa,
Robert Carroll, Yair Movshovitz-Attias, Jonathan T. Barron, Yael Pritch,
Marc Levoy
ACM Transactions on Graphics 37(4),
(Proc. SIGGRAPH 2018)
Click here for an earlier article in the
Google Research Blog.
And here for articles on
learning-based depth
(published in
Proc. ICCV 2019)
and
dual-pixel + dual-camera
(published in
Proc. ECCV 2020).
Click here for an
API for reading
dual-pixels from Pixel phones.
|
Shallow depth-of-field is commonly used by photographers to isolate a subject
from a distracting background. However, standard cell phone cameras cannot
produce such images optically, as their short focal lengths and small apertures
capture nearly all-in-focus images. We present a system to computationally
synthesize shallow depth-of-field images with a single mobile camera and a
single button press. If the image is of a person, we use a person segmentation
network to separate the person and their accessories from the background. If
available, we also use dense dual-pixel auto-focus hardware, effectively a
2-sample light field with an approximately 1 millimeter baseline, to compute a
dense depth map. These two signals are combined and used to render a defocused
image. Our system can process a 5.4 megapixel image in 4 seconds on a mobile
phone, is fully automatic, and is robust enough to be used by non-experts. The
modular nature of our system allows it to degrade naturally in the absence of a
dual-pixel sensor or a human subject.
|
|

|
Portrait mode on the Pixel 2 and Pixel 2 XL smartphones
Marc Levoy,
Yael Pritch
Google Research blog,
October 17, 2017.
Click here for a
feeder article in
Google's blog,
The Keyword.
And here for another blog post, giving
10 tips for using portrait mode.
See also our follow-on
paper in SIGGRAPH 2018.
|
Portrait mode, a major feature of the new Pixel 2 and Pixel 2 XL smartphones,
allows anyone to take professional-looking shallow depth-of-field images. This
feature helped both devices earn
DxO's
highest mobile camera ranking, and works
with both the rear-facing and front-facing cameras, even though neither is
dual-camera (normally required to obtain this effect). [In this article] we
discuss the machine learning and computational photography techniques behind
this feature.
|
|

|
Burst photography for high dynamic range and low-light imaging on mobile cameras,
Samuel W. Hasinoff,
Dillon Sharlet,
Ryan Geiss,
Andrew Adams,
Jonathan T. Barron,
Florian Kainz,
Jiawen Chen,
Marc Levoy
Proc SIGGRAPH Asia 2016.
Click here for
Supplemental material,
and for an
archive of burst photography data
and a
blog about it.
And here for a blog about
Live HDR+,
the real-time, learning-based approximation of HDR+ used to make
Pixel 4's viewfinder WYSIWYG relative to the final HDR+ photo.
And a 2021 blog about adding
bracketing to HDR+.
|
Cell phone cameras have small apertures, which limits the number of photons
they can gather, leading to noisy images in low light. They also have small
sensor pixels, which limits the number of electrons each pixel can store,
leading to limited dynamic range. We describe a computational photography
pipeline that captures, aligns, and merges a burst of frames to reduce noise
and increase dynamic range. Our solution differs from previous HDR systems in
several ways. First, we do not use bracketed exposures. Instead, we capture
frames of constant exposure, which makes alignment more robust, and we set this
exposure low enough to avoid blowing out highlights. The resulting merged image
has clean shadows and high bit depth, allowing us to apply standard HDR tone
mapping methods. Second, we begin from Bayer raw frames rather than the
demosaicked RGB (or YUV) frames produced by hardware Image Signal Processors
(ISPs) common on mobile platforms. This gives us more bits per pixel and allows
us to circumvent the ISP's unwanted tone mapping and spatial denoising. Third,
we use a novel FFT-based alignment algorithm and a hybrid 2D/3D Wiener filter
to denoise and merge the frames in a burst. Our implementation is built atop
Android's Camera2 API, which provides per-frame camera control and access to
raw imagery, and is written in the Halide domain-specific language (DSL). It
runs in 4 seconds on device (for a 12 Mpix image), requires no user
intervention, and ships on several mass-produced cell phones.
|
|

|
Simulating the Visual Experience of Very Bright and Very Dark Scenes,
David E. Jacobs,
Orazio Gallo,
Emily A. Cooper,
Kari Pulli,
Marc Levoy
ACM Transactions on Graphics 34(3),
April 2015.
|
The human visual system can operate in a wide range of illumination levels, due
to several adaptation processes working in concert. For the most part, these
adaptation mechanisms are transparent, leaving the observer unaware of his or
her absolute adaptation state. At extreme illumination levels, however, some of
these mechanisms produce perceivable secondary effects, or epiphenomena. In
bright light, these include bleaching afterimages and adaptation afterimages,
while in dark conditions these include desaturation, loss of acuity, mesopic
hue shift, and the Purkinje effect. In this work we examine whether displaying
these effects explicitly can be used to extend the apparent dynamic range of a
conventional computer display. We present phenomenological models for each
effect, we describe efficient computer graphics methods for rendering our
models, and we propose a gaze-adaptive display that injects the effects into
imagery on a standard computer monitor. Finally, we report the results of
psychophysical experiments, which reveal that while mesopic epiphenomena are a
strong cue that a stimulus is very dark, afterimages have little impact on
perception that a stimulus is very bright.
|
|

|
HDR+: Low Light and High Dynamic Range photography in the Google Camera App
Marc Levoy
Google Research blog,
October 27, 2014.
See also this
SIGGRAPH Asia 2016 paper.
|
As anybody who has tried to use a smartphone to photograph a dimly lit scene
knows, the resulting pictures are often blurry or full of random variations in
brightness from pixel to pixel, known as image noise. Equally frustrating are
smartphone photographs of scenes where there is a large range of brightness
levels, such as a family photo backlit by a bright sky. In high dynamic range
(HDR) situations like this, photographs will either come out with an
overexposed sky (turning it white) or an underexposed family (turning them into
silhouettes). HDR+ is a feature in the Google Camera app for Nexus 5 and Nexus
6 that uses computational photography to help you take better pictures in these
common situations. When you press the shutter button, HDR+ actually captures a
rapid burst of pictures, then quickly combines them into one. This improves
results in both low-light and high dynamic range situations. [In this article]
we delve into each case and describe how HDR+ works to produce a better
picture.
|
|

|
Gyro-Based Multi-Image Deconvolution for Removing Handshake Blur,
Sung Hee Park,
Marc Levoy
Proc. CVPR 2014
Click here for the associated tech report on
handling moving objects and over-exposed regions.
|
Image deblurring to remove blur caused by camera shake has been intensively
studied. Nevertheless, most methods are brittle and computationally
expensive. In this paper we analyze multi-image approaches, which capture and
combine multiple frames in order to make deblurring more robust and
tractable. In particular, we compare the performance of two approaches:
align-and-average and multi-image deconvolution. Our deconvolution is
non-blind, using a blur model obtained from real camera motion as measured by a
gyroscope. We show that in most situations such deconvolution outperforms
align-and-average. We also show, perhaps surprisingly, that deconvolution does
not benefit from increasing exposure time beyond a certain threshold. To
demonstrate the effectiveness and efficiency of our method, we apply it to
still-resolution imagery of natural scenes captured using a mobile camera with
flexible camera control and an attached gyroscope.
|
|

|
WYSIWYG Computational Photography via Viewfinder Editing,
Jongmin Baek,
Dawid Pająk,
Kihwan Kim,
Kari Pulli,
Marc Levoy
ACM Transactions on Graphics
(Proc. SIGGRAPH Asia 2013)
|
Digital cameras with electronic viewfinders provide a relatively faithful
depiction of the final image, providing a WYSIWYG experience. If, however, the
image is created from a burst of differently captured images, or non-linear
interactive edits significantly alter the final outcome, then the photographer
cannot directly see the results, but instead must imagine the post-processing
effects. This paper explores the notion of viewfinder editing, which makes the
viewfinder more accurately reflect the final image the user intends to
create. We allow the user to alter the local or global appearance (tone, color,
saturation, or focus) via stroke-based input, and propagate the edits
spatiotemporally. The system then delivers a real-time visualization of these
modifications to the user, and drives the camera control routines to select
better capture parameters.
|
|
|
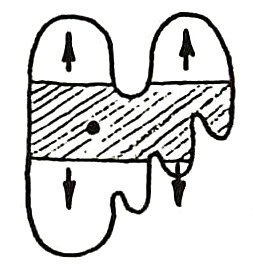
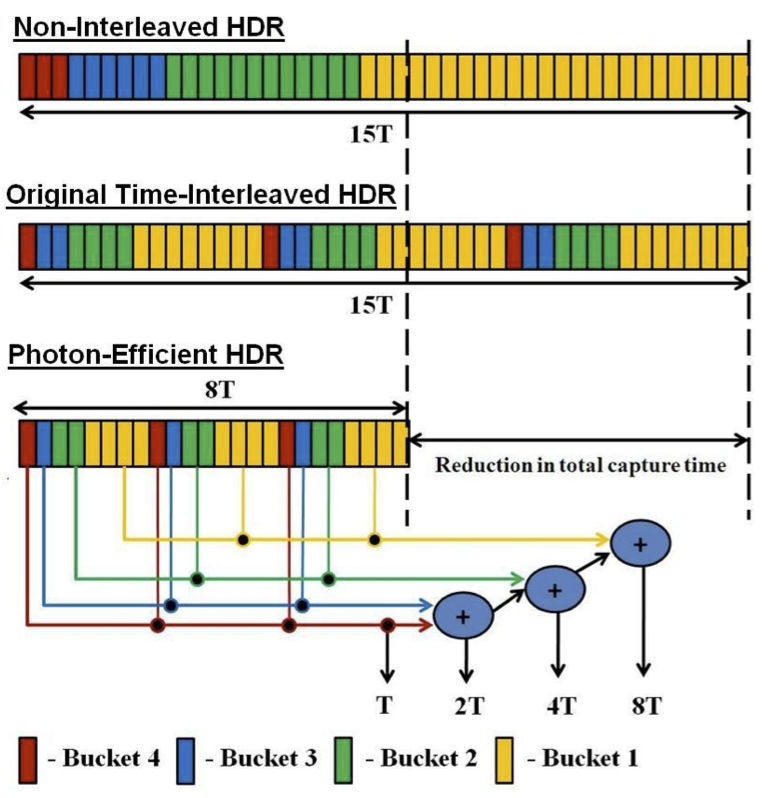
Applications of Multi-Bucket Sensors to Computational Photography,
Gordon Wan,
Mark Horowitz,
Marc Levoy
Stanford Computer Graphics Laboratory Technical Report 2012-2
Later appeared in
IEEE JSSC, Vol. 47, No. 4, April 2012.
|
Many computational photography techniques take the form, "Capture a burst of
images varying camera setting X (exposure, gain, focus, lighting), then align
and combine them to produce a single photograph exhibiting better Y (dynamic
range, signal-to-noise, depth of field). Unfortunately, these techniques may
fail on moving scenes because the images are captured sequentially, so objects
are in different positions in each image, and robust local alignment is
difficult to achieve. To overcome this limitation, we propose using
multi-bucket sensors, which allow the images to be captured in
time-slice-interleaved fashion. This interleaving produces images with nearly
identical positions for moving objects, making alignment unnecessary. To test
our proposal, we have designed and fabricated a 4-bucket, VGA-resolution CMOS
image sensor, and we have applied it to high dynamic range (HDR)
photography. Our sensor permits 4 different exposures to be captured at once
with no motion difference between the exposures. Also, since our protocol
employs non-destructive analog addition of time slices, it requires less total
capture time than capturing a burst of images, thereby reducing total motion
blur. Finally, we apply our multi-bucket sensor to several other computational
photography applications, including flash/no-flash, multi-flash, and flash
matting.
|
|

|
Focal stack compositing for depth of field control,
David E. Jacobs,
Jongmin Baek,
Marc Levoy
Stanford Computer Graphics Laboratory Technical Report 2012-1
|
Many cameras provide insufficient control over depth of field. Some have a
fixed aperture; others have a variable aperture that is either too small or too
large to produce the desired amount of blur. To overcome this limitation, one
can capture a focal stack, which is a collection of images each focused at a
different depth, then combine these slices to form a single composite that
exhibits the desired depth of field. In this paper, we present a theory of
focal stack compositing, and algorithms for computing images with extended
depth of field, shallower depth of field than the lens aperture naturally
provides, or even freeform (non-physical) depth of field. We show that while
these composites are subject to halo artifacts, there is a principled
methodology for avoiding these artifacts - by feathering a slice selection map
according to certain rules before computing the composite image.
|
|

|
Halide: decoupling algorithms from schedules for high performance image processing,
Jonathan Ragan-Kelley,
Andrew Adams,
Connelly Barnes, Dillon Sharlet,
Sylvain Paris,
Marc Levoy,
Saman Amarasinghe,
Fredo Durand
CACM, January 2018, with an introductory
technical perspective by Manuel Chakravarty.
See also original paper in SIGGRAPH 2012 (entry below this one).
|
Writing high-performance code on modern machines requires not just locally
optimizing inner loops, but globally reorganizing compu- tations to exploit
parallelism and locality—doing things like tiling and blocking whole pipelines
to fit in cache. This is especially true for image processing pipelines, where
individual stages do much too little work to amortize the cost of loading and
storing results to and from off-chip memory. As a result, the performance
differ- ence between a naive implementation of a pipeline and one globally
optimized for parallelism and locality is often an order of mag-
nitude. However, using existing programming tools, writing high- performance
image processing code requires sacrificing simplicity, portability, and
modularity. We argue that this is because traditional programming models
conflate what computations define the algo- rithm, with decisions about storage
and the order of computation, which we call the schedule. We propose a new
programming language for image process- ing pipelines, called Halide, that
separates the algorithm from its schedule. Programmers can change the schedule
to express many possible organizations of a single algorithm. The Halide
compiler automatically synthesizes a globally combined loop nest for an en-
tire algorithm, given a schedule. Halide models a space of schedules which is
expressive enough to describe organizations that match or outperform
state-of-the-art hand-written implementations of many computational photography
and computer vision algorithms. Its model is simple enough to do so often in
only a few lines of code, and small changes generate efficient implementations
for x86 and ARM multicores, GPUs, and specialized image processors, all from a
single algorithm. Halide has been public and open source for over four years,
during which it has been used by hundreds of programmers to deploy code to tens
of thousands of servers and hundreds of millions of phones, processing billions
of images every day.
|
|

|
Decoupling algorithms from schedules for easy optimization of image processing pipelines,
Jonathan Ragan-Kelley,
Andrew Adams,
Sylvain Paris,
Marc Levoy,
Saman Amarasinghe,
Fredo Durand
ACM Transactions on Graphics 31(4)
(Proc. SIGGRAPH 2012).
Click here for more information on the
Halide language.
Its compiler is open source and actively supported.
You might also be
interested in our SIGGRAPH 2014 paper on
Darkroom: compiling a Halide-like language into hardware pipelines.
See also reprint in CACM 2018 (entry above this one).
Included in
Seminal Graphics Papers, Volume 2.
|
Using existing programming tools, writing high-performance image processing
code requires sacrificing readability, portability, and modularity. We argue
that this is a consequence of conflating what computations define the
algorithm, with decisions about storage and the order of computation. We refer
to these latter two concerns as the schedule, including choices of tiling,
fusion, recomputation vs. storage, vectorization, and parallelism.
We propose a representation for feed-forward imaging pipelines that separates
the algorithm from its schedule, enabling high-performance without sacrificing
code clarity. This decoupling simplifies the algorithm specification: images
and intermediate buffers become functions over an infinite integer domain, with
no explicit storage or boundary conditions. Imaging pipelines are compositions
of functions. Programmers separately specify scheduling strategies for the
various functions composing the algorithm, which allows them to efficiently
explore different optimizations without changing the algorithmic code.
We demonstrate the power of this representation by expressing a range of recent
image processing applications in an embedded domain specific language called
Halide, and compiling them for ARM, x86, and GPUs. Our compiler targets SIMD
units, multiple cores, and complex memory hierarchies. We demonstrate that it
can handle algorithms such as a camera raw pipeline, the bilateral grid, fast
local Laplacian filtering, and image segmentation. The algorithms expressed in
our language are both shorter and faster than state-of-the-art implementations.
|
|
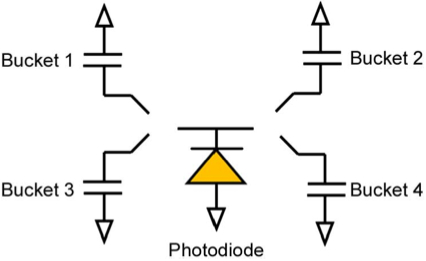
|
CMOS Image Sensors With Multi-Bucket Pixels for Computational Photography,
Gordon Wan,
Xiangli Li,
Gennadiy Agranov,
Marc Levoy,
Mark Horowitz
IEEE Journal of Solid-State Circuits,
Vol. 47, No. 4, April, 2012, pp. 1031-1042.
|
This paper presents new image sensors with multi-bucket pixels that enable
time-multiplexed exposure, an alternative imaging approach. This approach deals
nicely with scene motion, and greatly improves high dynamic range imaging,
structured light illumination, motion corrected photography, etc. To implement
an in-pixel memory or a bucket, the new image sensors incorporate the virtual
phase CCD concept into a standard 4-transistor CMOS imager pixel. This design
allows us to create a multi-bucket pixel which is compact, scalable, and
supports true correlated double sampling to cancel kTC noise. Two image
sensors with dual and quad-bucket pixels have been designed and fabricated. The
dual-bucket sensor consists of a array of 5.0 m pixel in 0.11 m CMOS technology
while the quad-bucket sensor comprises array of 5.6 m pixel in 0.13 m CMOS
technology. Some computational photography applications were implemented using
the two sensors to demonstrate their values in eliminating artifacts that
currently plague computational photography.
|
|


|
Digital Video Stabilization and Rolling Shutter Correction using Gyroscopes,
Alexandre Karpenko,
David E. Jacobs,
Jongmin Baek,
Marc Levoy
Stanford Computer Science Tech Report CSTR 2011-03,
September, 2011.
Click here for the
source code.
|
In this paper we present a robust, real-time video stabilization and rolling
shutter correction technique based on commodity gyroscopes. First, we develop a
unified algorithm for modeling camera motion and rolling shutter warping. We
then present a novel framework for automatically calibrating the gyroscope and
camera outputs from a single video capture. This calibration allows us to use
only gyroscope data to effectively correct rolling shutter warping and to
stabilize the video. Using our algorithm, we show results for videos featuring
large moving foreground objects, parallax, and low-illumination. We also
compare our method with commercial image-based stabilization algorithms. We
find that our solution is more robust and computationally inexpensive. Finally,
we implement our algorithm directly on a mobile phone. We demonstrate that by
using the phone's inbuilt gyroscope and GPU, we can remove camera shake and
rolling shutter artifacts in real-time.
|
|


|
Experimental Platforms for Computational Photography
Marc Levoy
IEEE Computer Graphics and Applications,
Vol. 30, No. 5, September/October, 2010, pp. 81-87.
If you're looking for our SIGGRAPH 2010 paper on the Frankencamera,
it's the next paper on this web page.
|
Although interest in computational photography has steadily increased among
graphics and vision researchers, few of these techniques have found their way
into commercial cameras. In this article I offer several possible
explanations, including barriers to entry that arise from the current structure
of the photography industry, and an incompleteness and lack of robustness in
current computational photography techniques. To begin addressing these
problems, my laboratory has designed an open architecture for programmable
cameras (called Frankencamera), an API (called FCam) with bindings for C++, and
two reference implementations: a Nokia N900 smartphone with a modified software
stack and a custom camera called the Frankencamera F2. Our short-term goal is
to standardize this architecture and distribute our reference platforms to
researchers and students worldwide. Our long-term goal is to help create an
open-source camera community, leading eventually to commercial cameras that
accept plugins and apps. I discuss the steps that might be needed to bootstrap
this community, including scaling up the world's educational programs in
photographic technology. Finally, I talk about some of future research
challenges in computational photography.
|
|


|
The Frankencamera: An Experimental Platform for Computational Photography
Andrew Adams,
Eino-Ville (Eddy) Talvala,
Sung Hee Park,
David E. Jacobs,
Boris Ajdin,
Natasha Gelfand,
Jennifer Dolson,
Daniel Vaquero,
Jongmin Baek,
Marius Tico,
Henrik P.A. Lensch,
Wojciech Matusik,
Kari Pulli,
Mark Horowitz,
Marc Levoy
Proc. SIGGRAPH 2010.
Reprinted in
CACM, November 2012, with an introductory
technical perspective by Richard Szeliski
If you're looking for our release of the FCam API for the camera on the Nokia
N900 smartphone, click here.
|
Although there has been much interest in computational photography within the
research and photography communities, progress has been hampered by the lack of
a portable, programmable camera with sufficient image quality and computing
power. To address this problem, we have designed and implemented an open
architecture and API for such cameras: the Frankencamera. It consists of a base
hardware specification, a software stack based on Linux, and an API for
C++. Our architecture permits control and synchronization of the sensor and
image processing pipeline at the microsecond time scale, as well as the ability
to incorporate and synchronize external hardware like lenses and flashes. This
paper specifies our architecture and API, and it describes two reference
implementations we have built. Using these implementations we demonstrate six
computational photography applications: HDR viewfinding and capture, low-light
viewfinding and capture, automated acquisition of extended dynamic range
panoramas, foveal imaging, IMU-based hand shake detection, and
rephotography. Our goal is to standardize the architecture and distribute
Frankencameras to researchers and students, as a step towards creating a
community of photographer-programmers who develop algorithms, applications, and
hardware for computational cameras.
|
|
|
Gaussian KD-Trees for Fast High-Dimensional Filtering
Andrew Adams
Natasha Gelfand,
Jennifer Dolson,
Marc Levoy
ACM Transactions on Graphics 28(3),
Proc. SIGGRAPH 2009
A follow-on paper, which filters in high-D using a
permutohedral lattice, was runner-up for best paper
at Eurographics 2010.
|
We propose a method for accelerating a broad class of non-linear filters that
includes the bilateral, non-local means, and other related filters. These
filters can all be expressed in a similar way: First, assign each value to be
filtered a position in some vector space. Then, replace every value with a
weighted linear combination of all val- ues, with weights determined by a
Gaussian function of distance between the positions. If the values are pixel
colors and the posi- tions are (x, y) coordinates, this describes a Gaussian
blur. If the positions are instead (x, y, r, g, b) coordinates in a
five-dimensional space-color volume, this describes a bilateral filter. If we
instead set the positions to local patches of color around the associated
pixel, this describes non-local means. We describe a Monte-Carlo kd- tree
sampling algorithm that efficiently computes any filter that can be expressed
in this way, along with a GPU implementation of this technique. We use this
algorithm to implement an accelerated bilat- eral filter that respects full 3D
color distance; accelerated non-local means on single images, volumes, and
unaligned bursts of images for denoising; and a fast adaptation of non-local
means to geome- try. If we have n values to filter, and each is assigned a
position in a d-dimensional space, then our space complexity is O(dn) and our
time complexity is O(dn log n), whereas existing methods are typically either
exponential in d or quadratic in n.
|
|

|
Spatially Adaptive Photographic Flash
Rolf Adelsberger, Remo Ziegler,
Marc Levoy,
Markus Gross
Technical Report 612, ETH Zurich, Institute of Visual Computing,
December 2008.
|
Using photographic flash for candid shots often results in an unevenly lit
scene, in which objects in the back appear dark. We describe a spatially
adaptive photographic flash system, in which the intensity of illumination
varies depending on the depth and reflectivity of features in the scene. We
adapt to changes in depth using a single-shot method, and to changes in
reflectivity using a multi-shot method. The single-shot method requires only
a depth image, whereas the multi-shot method requires at least one color image
in addition to the depth data. To reduce noise in our depth images, we present
a novel filter that takes into account the amplitude-dependent noise
distribution of observed depth values. To demonstrate our ideas, we have built
a prototype consisting of a depth camera, a flash light, an LCD and a
lens. By attenuating the flash using the LCD, a variety of illumination
effects can be achieved.
|
|

|
Veiling Glare in High Dynamic Range Imaging
Eino-Ville (Eddy)
Talvala,
Andrew Adams,
Mark Horowitz,
Marc Levoy
ACM Transactions on Graphics 26(3),
Proc. SIGGRAPH 2007
|
The ability of a camera to record a high dynamic range image, whether by taking
one snapshot or a sequence, is limited by the presence of veiling glare - the
tendency of bright objects in the scene to reduce the contrast everywhere
within the field of view. Veiling glare is a global illumination effect that
arises from multiple scattering of light inside the camera's optics, body, and
sensor. By measuring separately the direct and indirect components of the
intra-camera light transport, one can increase the maximum dynamic range a
particular camera is capable of recording. In this paper, we quantify the
presence of veiling glare and related optical artifacts for several types of
digital cameras, and we describe two methods for removing them: deconvolution
by a measured glare spread function, and a novel direct-indirect separation of
the lens transport using a structured occlusion mask. By physically blocking
the light that contributes to veiling glare, we attain significantly higher
signal to noise ratios than with deconvolution. Finally, we demonstrate our
separation method for several combinations of cameras and realistic scenes.
|
|

|
Interactive Design of Multi-Perspective Images
for Visualizing Urban Landscapes
Augusto Román,
Gaurav Garg,
Marc Levoy
Proc. Visualization 2004
This project was the genesis of Google's StreetView;
see this
historical note for details.
In a follow-on paper in
EGSR 2006, Augusto Román and Hendrik Lensch describe
an automatic way to compute these multi-perspective panoramas.
|
Multi-perspective images are a useful representation of extended, roughly
planar scenes such as landscapes or city blocks. However, constructing
effective multi-perspective images is something of an art. In this paper, we
describe an interactive system for creating multi-perspective images composed
of serially blended cross-slits mosaics. Beginning with a sideways-looking
video of the scene as might be captured from a moving vehicle, we allow the
user to interactively specify a set of cross-slits cameras, possibly with gaps
between them. In each camera, one of the slits is defined to be the camera
path, which is typically horizontal, and the user is left to choose the second
slit, which is typically vertical. The system then generates intermediate views
between these cameras using a novel interpolation scheme, thereby producing a
multi-perspective image with no seams. The user can also choose the picture
surface in space onto which viewing rays are projected, thereby establishing a
parameterization for the image. We show how the choice of this surface can be
used to create interesting visual effects. We demonstrate our system by
constructing multi-perspective images that summarize city blocks, including
corners, blocks with deep plazas and other challenging urban situations.
|